The AI-Native Development Maturity Model
From Code Speed to Specification Quality: A framework for understanding how organizations can effectively integrate AI into their development processes without falling into the efficiency paradox.
Issam Gharios, Co-Founder & CEO — SenzoStack
Rashid Shaikh, Co-Founder & CTO — SenzoStack
“The pace of change has never been this fast, yet it will never be this slow again.”
— Justin Trudeau
I. The Efficiency Paradox
Something has shifted in how software gets built. In the span of eighteen months, AI coding assistants have gone from curiosity to default. Engineering teams across every sector now generate code faster than at any point in the history of the profession.
And yet, for most organizations, the results have been disappointing.
The Code Generation Trap
The premise of most AI coding tool marketing is straightforward: developers spend too much time writing boilerplate, and AI can write it faster. This is true. But it misses the point.
The 2025 DORA State of AI-Assisted Software Development Report found that while over 90% of developers have adopted AI-assisted tools, delivery stability has not improved at the same rate. The report concluded that organizations with strong engineering fundamentals see AI amplify those strengths, while organizations with weak fundamentals see AI amplify their weaknesses. As the researchers put it, AI does not fix a broken team; it makes the cracks more visible.
The pattern is confirmed by telemetry data at scale. Research from Faros AI, analyzing data from over ten thousand developers, identified what they termed the AI Productivity Paradox: individual task completion rose by 21%, pull request volume increased by 98%, but organizational delivery metrics remained flat. More output was not translating into more outcomes.
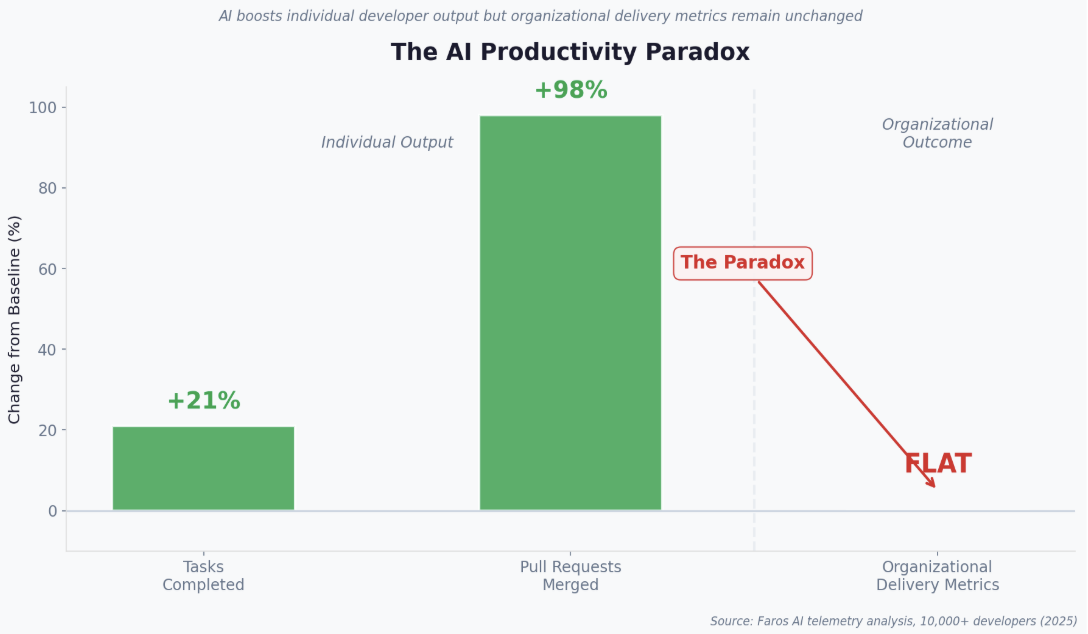
Figure 1: The AI Productivity Paradox — individual output rises while organizational delivery stalls
The bottleneck was never code generation. It was everything around it: unclear requirements, review processes that cannot keep pace with output volume, cross-functional handoffs that stall implementation mid-flight, and a growing inability to trace what was generated by whom and why. Teams that bolted AI into their existing workflows discovered that faster output without structural adaptation produces more rework, not less.
Quotient’s AI Adoption Maturity Model for Engineering Organizations (2026) provides a valuable framework for assessing organizational readiness across six capability dimensions: enablement, governance, validation, workflow integration, automation, and data context. Their key insight, that Stage 3 or 4 may be the optimal near-term target for most organizations, aligns with what we observed. But organizational readiness models answer one question: is your organization ready for AI?
This whitepaper answers the question: is your team using AI in a way that actually produces better outcomes?
Case Study: The Tenant Deletion Failure
This paper is grounded in hands-on experimentation, not theory. Over the past several months, our team at SenzoStack has systematically tested AI-driven development tools across multiple categories. We conducted structured interviews with engineering leaders at companies of varying sizes. We implemented real features using agentic workflows. And we identified systemic gaps in the current tooling landscape that no existing solution adequately addresses.
One exercise illustrates the core problem. Our team used Claude Code to implement a tenant deletion feature—a function that removes a tenant from the UI and cleans up associated database records. This is not a complex feature in terms of logic. But it is delicate: it touches multiple layers of the stack, requires careful sequencing, and has irreversible consequences if done incorrectly.
What would have taken a team weeks of careful manual implementation was generated in a fraction of that time. The AI correctly identified the files to modify, generated the deletion logic across UI and backend layers, and produced working code.
Then it stopped and asked a product question: should a deleted tenant be marked as disabled in the UI, or completely hidden?
This is the moment that matters. The AI did not hallucinate an answer. It recognized that a product decision was needed and surfaced it. But implementation was now paused, waiting for a product manager who was not part of the session. There was no mechanism to bring them in, capture their decision, and resume without breaking context.
The code generation was the easy part. The operating model failure was the hard part. And this pattern, where AI accelerates execution but exposes coordination gaps, repeats across every team we studied.
We envision that in the new world where code generation is fast, one of the primary bottlenecks will be getting information from one function to another. A developer is generating code and a question surfaces where a product manager is needed. Implementation pauses. Context is lost. The handoff tax compounds.
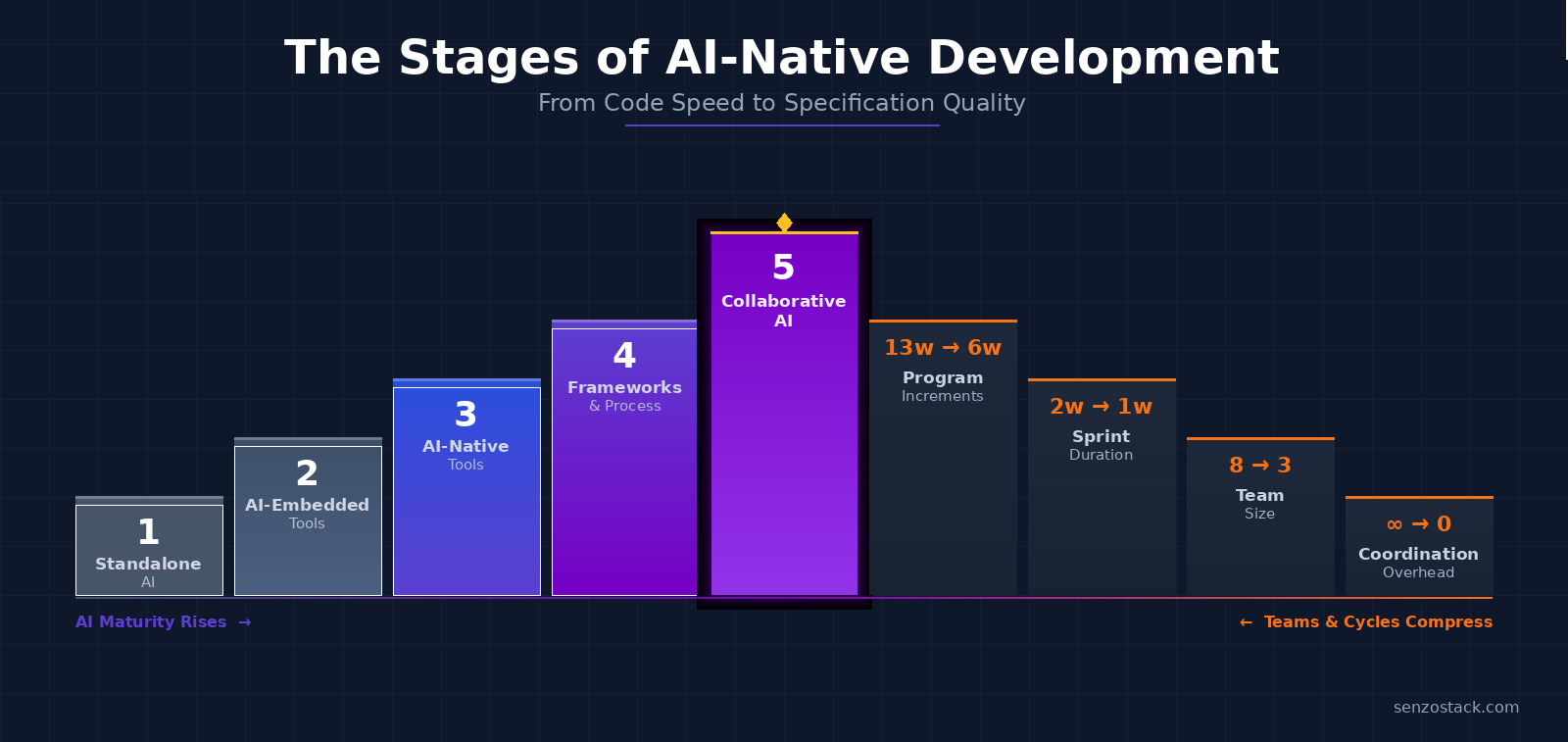
II. The Five-Tier AI Development Maturity Model
Through our experimentation and interviews, we identified five distinct categories of AI development tooling. These are not simply stages that every team passes through sequentially. They represent fundamentally different approaches to integrating AI into the software delivery process, each with distinct tradeoffs.
The model is organized around two axes: who drives the workflow (human or AI), and whether the development process itself changes. This distinction matters because tools that embed AI into an existing workflow produce fundamentally different results than tools that reshape the workflow around AI’s capabilities.
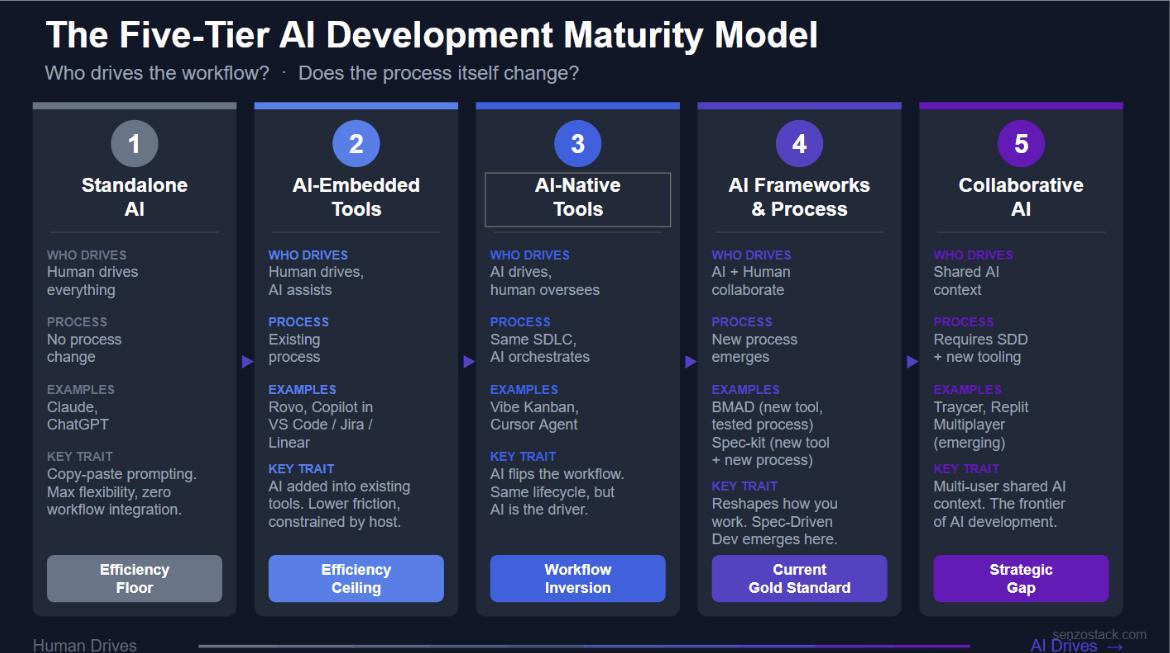
Figure 2: The Five-Tier AI Development Maturity Model
Categories 1 & 2: The Efficiency Ceiling
| Category | Who Drives | Process Change | Examples |
|---|---|---|---|
| Standalone AI | Human drives everything | None | Claude, ChatGPT |
| AI-Embedded Tools | Human drives, AI assists | Existing process | Rovo, Copilot in VS Code / Jira / Linear |
Category 1: Standalone AI
This is where most teams begin. A developer opens a chat interface, pastes in a prompt, receives generated code, and copies it back into their project. The interaction is entirely manual. There is no persistent context, no connection to the codebase, and no integration with the team’s workflow.
The value is real but narrow. Standalone AI excels at generating boilerplate, exploring unfamiliar APIs, drafting documentation, and rubber-ducking architectural decisions. It fails when the task requires codebase awareness, multi-step reasoning, or collaboration. The most significant limitation is the copy-paste boundary: every interaction starts from zero. For individual productivity on isolated tasks, Category 1 tools are effective. As a foundation for team-scale delivery, they are insufficient.
Category 2: AI-Embedded Tools
The natural next step is embedding AI directly into the tools teams already use: project management systems, communication platforms, and IDEs. GitHub Copilot’s integrations with Jira, Microsoft Teams, and Linear exemplify this approach, as does Atlassian’s Rovo and VS Code’s native chat capabilities.
We tested these integrations extensively. The onboarding experience varies; Jira integration requires Rovo, which adds cost and complexity; Linear is MCP-ready out of the box and significantly simpler to configure; Teams integration sits in between, with each user authenticating independently.
The core finding was consistent across all platforms: Category 2 tools jump straight to implementation. When assigned a ticket, the AI immediately begins branching and coding without validating whether the requirement is clear, the architecture is sound, or dependencies have been considered. It skips the thinking that should precede the doing. The result was functional code that technically satisfied the ticket description but missed the intent—the exact problem AI was supposed to eliminate.
Categories 1 and 2 represent an efficiency ceiling. They optimize the middle of the pipeline, code generation, without addressing the upstream clarity or downstream coordination that determines whether generated code creates value or rework.
Category 3: AI-Native Tools — The Workflow Inversion
| Category | Who Drives | Process Change | Examples |
|---|---|---|---|
| AI-Native Tools | AI drives, human oversees | Same SDLC, AI orchestrates | Vibe Kanban, Cursor Agent |
Category 3 marks a fundamental shift: the AI becomes the driver of the workflow, and the human moves into an oversight role. The development lifecycle itself does not change, teams still plan, build, review, and deploy, but who orchestrates the work flips.
Tools like Vibe Kanban (BloopAI) exemplify this pattern. Vibe Kanban combines a kanban board with isolated agent workspaces, allowing teams to plan work collaboratively through issues and then dispatch coding agents to execute in dedicated git worktrees. Multiple team members can assign issues, review diffs, and leave inline comments that are sent directly back to the agent. The tool integrates planning, agent execution, diff review, browser preview, and PR creation into a single interface.
Cursor’s Agent mode operates similarly: the developer describes intent, and the AI drives the implementation across multiple files, running tests and resolving errors autonomously. The human approves, redirects, or overrides.
The value of Category 3 is that it removes the developer from the mechanical execution loop while keeping them in the decision loop. The limitation is that these tools still operate within the existing SDLC framework. They accelerate execution but do not fundamentally change how requirements are specified, how architectural decisions are made, or how cross-functional knowledge flows into the process.
Category 4: AI Frameworks & Process — The Current Gold Standard
| Category | Who Drives | Process Change | Examples |
|---|---|---|---|
| AI Frameworks & Process | AI + Human collaborate | New process emerges | BMAD, spec-kit, Claude Code Skills |
Category 4 represents the most significant finding from our research. This is where both the tooling and the process change, and where teams are seeing the greatest returns.
The key insight came from our interviews. One engineering leader, managing a team that had developed over forty specialized skills for their AI workflows, articulated the principle clearly: the AI performs better when you break the problem down by phase. Instead of a single monolithic prompt, their team maintains separate skills for specification, design, architecture, code generation, and review. Each skill is optimized for its specific phase of the development lifecycle.
Within Category 4, we observed two distinct sub-patterns:
New Tool, Battle-Tested Process
BMAD takes a persona-driven approach, assigning distinct roles (product manager, architect, developer) to different phases of the workflow. It is comprehensive and can produce substantial output from a high-level idea. The tool is new, but the process it follows, structured PM and Agile frameworks, is well-established. This makes BMAD accessible to teams already familiar with role-based delivery. The tradeoff is that it is heavy: the framework demands significant user attention to guide the agent through its personas, and the overhead can slow teams that need to move quickly.
New Tool AND New Process
GitHub’s spec-kit introduces an entirely new methodology: Spec-Driven Development (SDD). Specifications are positioned not as disposable scaffolding but as executable artifacts that drive the entire implementation chain. The framework enforces a structured workflow: establish project principles, define specifications, create implementation plans, generate tasks, and only then execute. Both the tool and the way you work fundamentally change.
Claude Code’s skills system falls along this same spectrum. Teams write reusable, version-controlled prompt modules tailored to their codebase, conventions, and workflow. This proved to be the most flexible approach. However, skills degrade over time as the codebase grows. One team reported that after several hundred thousand lines of code, skills needed to be broken down into smaller, more targeted modules to remain effective.
The overarching lesson from Category 4 is that AI skill development is becoming a first-class engineering discipline. Teams that treat prompt engineering as an ad-hoc activity fall behind teams that codify, version, and maintain their AI instructions with the same rigor they apply to source code. The quality of AI output is directly proportional to the quality of the specification that precedes it.
Category 5: Collaborative AI — The Strategic Gap
| Category | Who Drives | Process Change | Examples |
|---|---|---|---|
| Collaborative AI | Shared AI context | Requires SDD + new tooling | Traycer, Replit Multiplayer (emerging) |
Category 5 is the frontier that does not yet exist in a mature form. And in our assessment, it represents the most critical gap in the current tooling landscape.
True Category 5 tooling requires two things simultaneously: a new development process like Spec-Driven Development as the foundation, and multi-user shared AI context that allows team members to collaborate within an AI session in real time. You cannot reach Category 5 by adding multiplayer to a Category 1 chat interface—you need the process evolution of Category 4 as the foundation.
Traycer
Traycer converts high-level intent into structured, editable specs before handing them to coding agents. Its plan-first model creates a natural collaboration surface: team members can review and refine specs before execution begins. However, the collaboration remains asynchronous. Traycer orchestrates agents well but does not provide real-time shared prompting. It is reaching toward Category 5 from a Category 4 foundation.
Replit Multiplayer
Replit offers the closest approximation to real-time collaborative AI development. Its Multiplayer mode allows multiple users to work in the same project simultaneously, with each collaborator able to start independent AI Agent threads that appear on a shared kanban board. The platform handles merge isolation automatically. The limitation is that Replit is a browser-based environment optimized for prototyping and smaller projects, not enterprise codebases with established toolchains.
We came into this research looking for a collaborative prompting solution, something where multiple team members could “vibe code” together, contributing prompts to a shared session with shared context. No tool we tested fully delivers this. Each approaches the problem from a different angle, but none provides the real-time shared AI context analogous to what Google Docs provides for document editing or Figma provides for design.
The collaboration tax is real and measurable. In our tenant deletion exercise, a product decision surfaced mid-implementation. The developer could not pull the product manager into the active AI session. Instead, they had to pause, context-switch to a different communication channel, wait for a response, and then manually reconstruct the context for the AI. This friction grows with team size and cross-functional complexity.
III. Redesigning the SDLC: Process Over Tools
One of the most striking patterns from our research is that the teams seeing the greatest returns from AI are not the ones with the best tools. They are the ones that have deliberately restructured their development process to match the realities of AI-accelerated delivery. Tool adoption without process adaptation produces friction, not flow.
The Incompatibility of Traditional Scrum
Two-week sprints were designed for human-paced work. When an agent can complete a sprint’s worth of implementation in a day, the ceremony overhead - planning poker, daily standups, retrospectives - becomes a constraint rather than a coordination mechanism. The rituals that once provided structure now impose drag.
The 2025 DORA report reinforces this finding. Their research identified Value Stream Management as a critical force multiplier for AI adoption, noting that organizations which redesigned their delivery flows around AI’s capabilities saw significantly better results than those that kept existing processes unchanged.
What Mature Teams Are Actually Doing
From our interviews, we observed mature AI-driven development teams compressing their delivery cadences in two ways:
Program Increments cut in half or more. Teams reported reducing PIs from approximately 13 weeks to around 6 weeks, with some compressing further to 4-week increments. The combination of AI-assisted specification and agent-driven execution means significantly less calendar time is needed to move from planning to working software.
Sprints compressed from two weeks to one week. Some teams are experimenting with sprints as short as a single day. At that cadence, the sprint becomes less of a planning container and more of a feedback loop — a mechanism for rapid course correction rather than batch delivery.
Some teams shelved timeboxing entirely. These teams told us they intend to return to structured cadences but need to remove the constraint temporarily while they adapt their operating model to AI-accelerated delivery. For very small teams of senior engineers with deep shared context, this can work. For teams beyond five or six people, the absence of structure leads to divergent work and integration surprises.
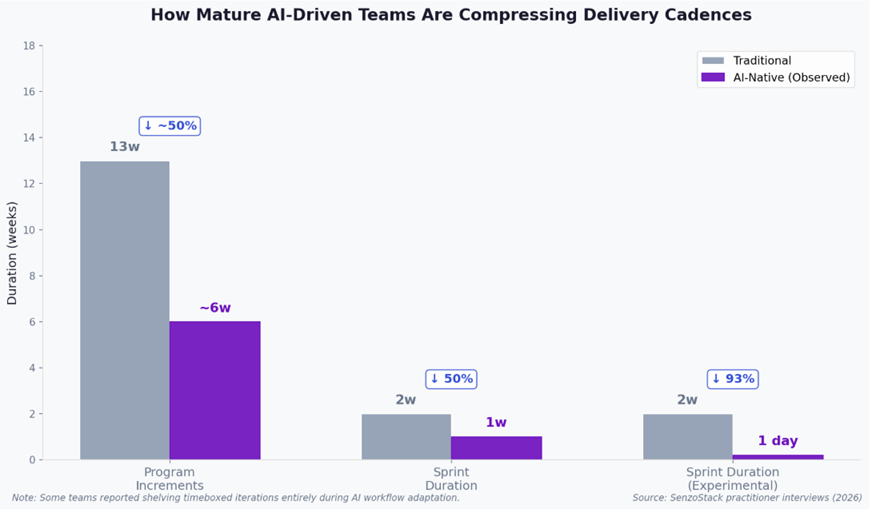
Figure 3: How mature AI-driven teams are compressing delivery cadences
The Four Process Postures
We observed four distinct process postures across the teams we studied, each producing different levels of AI benefit realization:
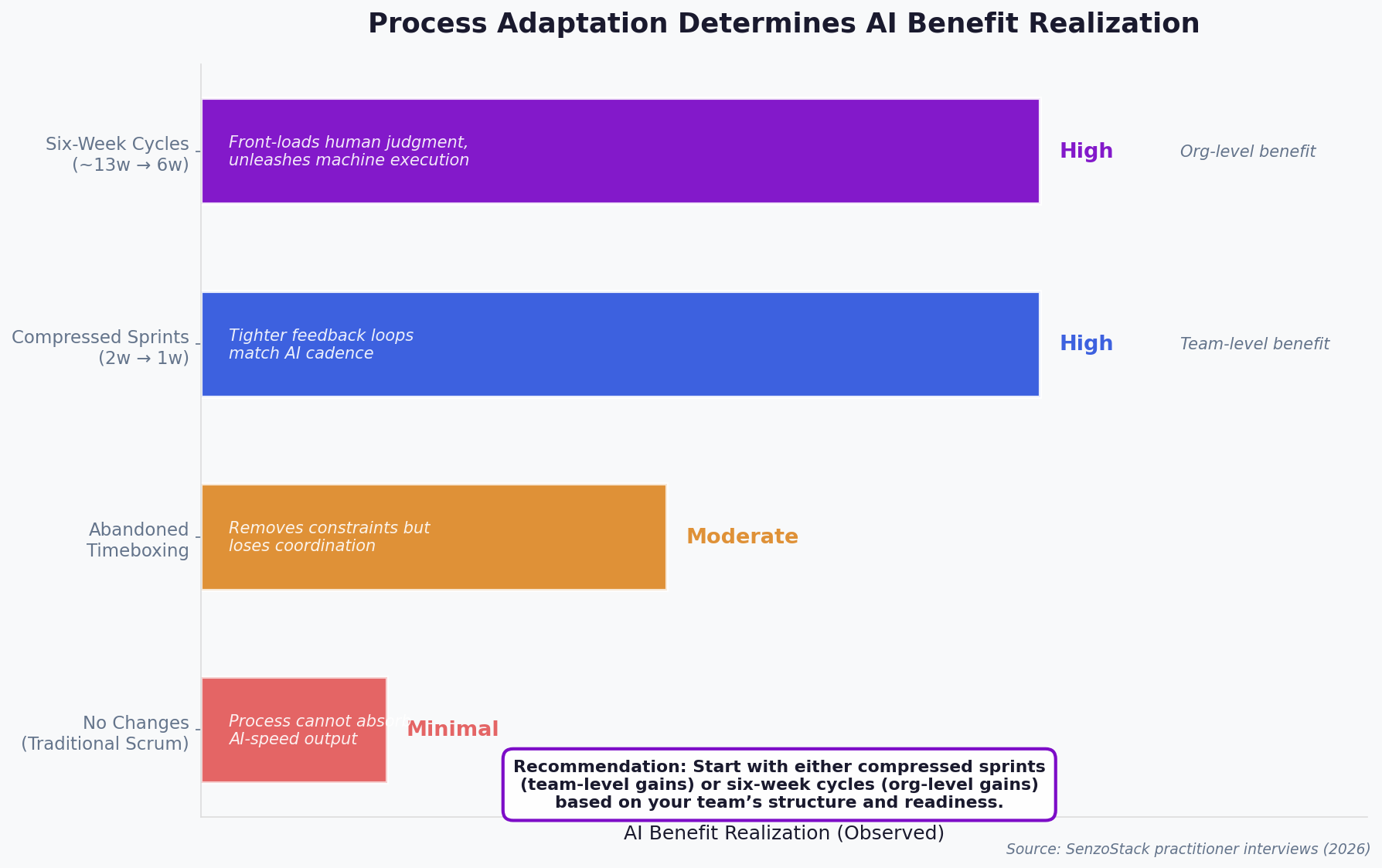
Figure 4: Process adaptation determines AI benefit realization
Both compressed sprints and six-week cycles produce high AI benefit realization, but at different organizational levels. Compressed sprints deliver team-level gains through tighter feedback loops that match AI’s speed of execution. Six-week cycles deliver organizational-level gains by front-loading human judgment, intent clarification, architectural decisions, priority alignment, and then unleashing machine-speed execution on a well-defined scope.
Our recommendation is that teams start with either approach, depending on their size, structure, and readiness. Both paths produce meaningful results. The critical decision is not which cadence to adopt but whether to adapt at all. Teams that make no changes see the least benefit.
The New Two-Pizza Team: Compressing Team Size
The original two-pizza rule, the idea that a team should be small enough to feed with two pizzas, typically six to eight people, was designed for a world where humans did all the work. In an AI-native environment, that arithmetic changes fundamentally.
When AI agents join the team as functional contributors, generating code, writing tests, drafting documentation, performing reviews, the total output capacity of the team increases dramatically. But so does the coordination overhead. An eight-person human team with two or three AI agents is not a ten-person team. It is an eight-person team drowning in machine-speed output that exceeds their collective capacity to review, integrate, and course-correct.
This is what we observed across multiple interviews. Teams of seven to eight human engineers using AI agents reported increased rework, not decreased. The agents generated code faster than the team could review it. Engineers stepped on each other’s toes as AI-generated changes cascaded across the same files. Merge conflicts multiplied. The coordination tax—standups, PR reviews, integration discussions—consumed more time, not less, because the volume of output requiring human judgment grew exponentially while the number of humans stayed constant.
The pattern became clear: the problem was not the agents. The problem was that the team was sized for a human-paced workflow and could not absorb machine-paced output.
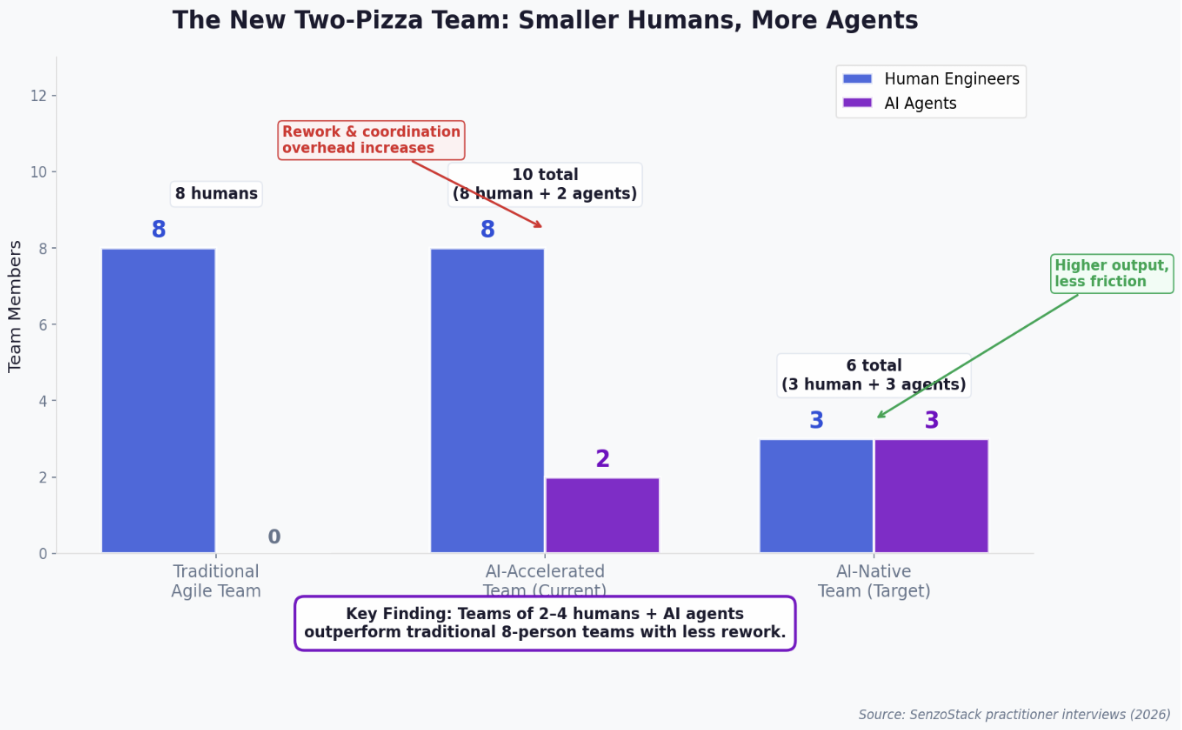
Figure 5: The new two-pizza team — fewer humans, more agents, less friction
The teams reporting the best results are converging on a new ideal: two to four human engineers working alongside AI agents. In this configuration, every human has a clear domain of responsibility with minimal overlap. Each engineer operates as an orchestrator, directing agents, reviewing output, making architectural decisions, rather than competing with teammates for the same files. The smaller the human team, the less coordination overhead, and the more effectively each person can absorb and direct the agent’s output.
This is not a layoff argument. It is a team design argument. The total capability of a three-person team with well-configured AI agents can exceed that of an eight-person team without them, not because the humans are redundant, but because the coordination cost of eight people reviewing, merging, and reconciling machine-speed output exceeds the value of having those additional reviewers. The constraint has shifted from “not enough hands to write code” to “too many hands trying to steer the same output.”
For engineering leaders, this has immediate implications for team formation. New projects and greenfield initiatives should be staffed with smaller, more senior teams from day one, with AI agents absorbing the implementation workload that would previously have required additional headcount. Existing teams may benefit from splitting into smaller, autonomous pods, each with their own agent configuration and domain boundary, rather than operating as a single large team with shared ownership of everything.
From Velocity to Visibility
Traditional delivery metrics were designed for human-paced work. Cycle time, throughput, and velocity assume that the pace of work is constrained by human capacity. When AI agents can generate pull requests, write tests, and propose architectural changes at machine speed, these metrics lose their signal. Story points become meaningless when the estimation unit was calibrated to human effort.
What leaders need instead are signals and actionable insights into the delivery process itself. Not dashboards that report what happened last sprint, but intelligence that identifies emerging risks before they materialize: requirements that are ambiguous enough to produce rework, pull requests that have stalled because of implicit cross-team dependencies, architectural decisions that are diverging across feature branches.
IV. Leadership Directive: Four Pillars for 2026
The transition to AI-native development is not a tool adoption exercise. It is an operating model redesign. Based on our research, we see four priorities for engineering leaders:
1. Specification as the Product
The teams producing the best results with AI are not the ones generating code fastest. They are the ones investing the most effort in clear, structured specifications before any code is generated. The specification is the product. The code is the artifact.
Leaders should evaluate their teams on the quality of inputs to AI, not the volume of outputs. In a world where code generation is nearly free, the value creation shifts entirely upstream: to the clarity of requirements, the precision of architectural constraints, and the completeness of acceptance criteria.
2. AI Infrastructure
Phase-specific skills, prompt libraries, and framework configurations are becoming as important as CI/CD pipelines and testing infrastructure. They need to be authored deliberately, version-controlled, reviewed, and maintained. Teams that treat this as ad-hoc work will find their AI effectiveness degrades as their codebase grows.
The engineering leader managing forty-plus skills in our interviews did not arrive at that number overnight. It was a deliberate investment in AI infrastructure, refined over months, with skills broken into smaller modules as the codebase scaled. This is the new infrastructure investment that separates high-performing teams from those that plateau at Category 2.
3. Cross-Functional Flow
The biggest productivity losses we observed were not in code generation. They were in the handoffs: developer-to-PM for product decisions, developer-to-architect for design validation, developer-to-reviewer for approval. AI accelerates everything between the handoffs but does nothing to accelerate the handoffs themselves.
The operating model must evolve to reduce this latency. Co-located planning sessions, embedded product decision-makers in engineering workflows, and asynchronous specification reviews that happen before implementation begins—these process changes matter more than any tool upgrade.
4. Use AI to Lead, Not Just to Build
Engineering leadership itself must be augmented by AI, and the benefits come in two distinct dimensions:
Reasoning. Static dashboards and point-in-time data snapshots are the old model. AI can synthesize signals across systems, pull request activity, deployment frequency, requirement change rates, review queue depth, and surface what matters in real time. Instead of leaders manually assembling status from six tools every Monday, AI reasoning can continuously identify emerging risks, shifting bottlenecks, and delivery patterns that would otherwise be invisible until the retrospective.
Generative. AI can internalize your team’s style, rules, values, and vision, and help you reshape direction and guide the team. This goes beyond dashboards into active leadership augmentation: generating onboarding materials that reflect your engineering culture, drafting architectural decision records that follow your conventions, producing sprint retrospective analyses that apply your team’s definition of improvement. AI becomes a thought partner for leaders, not just a code generator for engineers.
Leaders who adopt AI only for their teams’ code output but not for their own decision-making are leaving half the value on the table.
V. The SenzoStack Perspective
This paper reflects what we know today. Our research continues with additional team interviews, deeper experimentation with emerging frameworks, and ongoing refinement of the maturity model. What follows is our current thinking on where this is heading.
When to Use Which Model
Multiple maturity models now exist in this space, and they serve different purposes. Understanding which to apply and when is itself a leadership decision:
| Model Type | Use When You Need To… | Examples |
|---|---|---|
| Organizational Maturity Models | Assess governance readiness, enablement gaps, validation systems, and operational risk across the enterprise | Quotient AI Adoption Maturity Model, MIT CISR Enterprise AI Maturity Model |
| Tooling & Process Maturity Models | Decide what category of tool to adopt, evaluate whether your process can absorb AI-accelerated output, and restructure delivery cadence | SenzoStack AI-Native Development Maturity Model (this paper) |
Both types are needed. Organizational readiness without the right tooling and process produces well-governed teams that still move slowly. The right tools without governance produces fast teams that create new categories of risk. The most effective leaders apply both lenses.
Delivery Intelligence
The shift from velocity to visibility is not just a philosophical argument. It requires infrastructure. Teams need a connective layer that observes the flow of work across tools and surfaces the patterns that matter: requirements ambiguity that will produce rework, review bottlenecks that will delay releases, architectural divergence that will create integration debt.
This is the problem Senzo, our AI delivery intelligence agent, is designed to solve. Senzo integrates with Jira, GitHub, and Slack to surface delivery risks before they become delivery misses. It applies both reasoning—synthesizing signals across systems into actionable intelligence—and generative capabilities—producing recommendations aligned with the team’s standards and values.
What Comes Next
The maturity model we have outlined provides a framework for assessing where your team stands. Most organizations are operating in Categories 1 and 2, capturing individual productivity gains but struggling with systemic challenges. The leaders are moving into Categories 3 and 4, investing in AI-native tools and structured, phase-specific workflows that produce consistently better outcomes.
Category 5 remains the strategic gap. Collaborative AI development and delivery-level visibility are the next frontiers. The teams and tools that address these gaps will define the next phase of software engineering.
We will publish updated findings as our research continues.
About SenzoStack
SenzoStack designs and implements engineering operating models for AI-accelerated teams. We help organizations embed AI agents into their delivery systems so that acceleration produces leverage, not fragility.
To discuss how these findings apply to your organization, visit senzostack.com or reach out to schedule a strategy conversation.
References
- Google Cloud / DORA, “State of AI-Assisted Software Development Report,” 2025. https://dora.dev/dora-report-2025/ (The PDF version is also directly available at https://services.google.com/fh/files/misc/2025_state_of_ai_assisted_software_development.pdf)
- Quotient, “An AI Maturity Model for Engineering Teams,” 2026. https://www.getquotient.com/ai-maturity-model
- Faros AI, “The AI Productivity Paradox: Engineering Telemetry Analysis,” 2025. https://www.faros.ai/ai-productivity-paradox
- McKinsey & Company, “Unlocking the value of generative AI in software development,” 2025. https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/unlocking-the-value-of-ai-in-software-development
- GitHub, “spec-kit: Spec-Driven Development Framework,” 2026. https://github.com/github/spec-kit
- BloopAI, “Vibe Kanban,” 2026. https://github.com/BloopAI/vibe-kanban
- Justin Trudeau, attributed. Originally from a World Economic Forum address. https://www.weforum.org/stories/2018/01/pm-keynote-remarks-for-world-economic-forum-2018/ (The specific quote — “The pace of change has never been this fast, yet it will never be this slow again” — comes from his January 23, 2018 Davos keynote.)